DataK 2.0 Novedades

Novedades en DataK 2.0
El nuevo DataK 2.0 revoluciona sus conceptos básicos.
https://www.datalife.it
Tareas
En la primera versión, la tarea representaba una única operación ETL, como DB a DB, DB a archivo, archivo a DB, etc.
En la nueva versión la tarea se representa como una serie de operaciones básicas realizadas en secuencia que pueden combinarse entre sí, donde la salida de la anterior se utiliza como entrada en la siguiente.
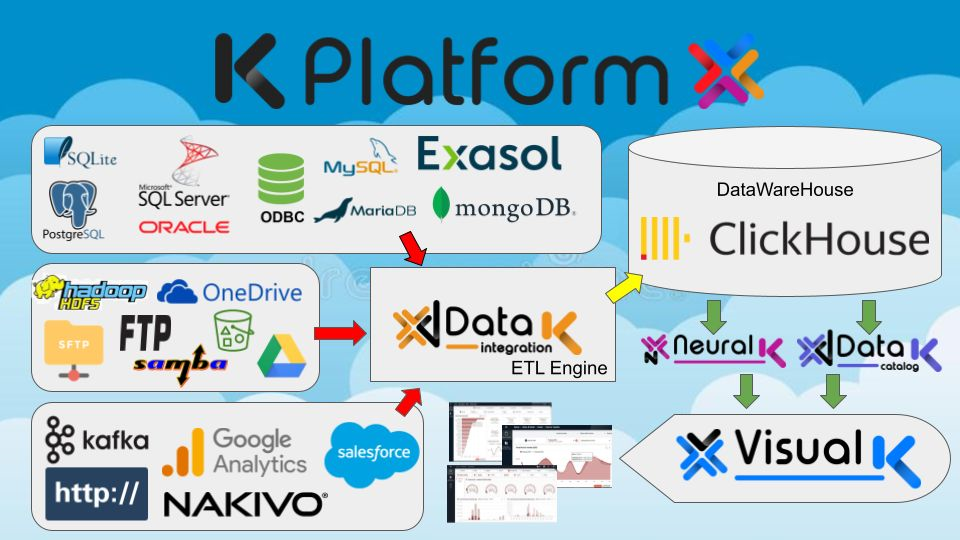
Estas operaciones básicas se dividen en 5 categorías:
- Bases de datos:
Le permiten leer/escribir, crear DLL o iniciar consultas SQL en bases de datos de varios tipos como:- PostgreSQL
- MariaDB
- MySQL
- Oracle
- MS SQL Server
- SQLite
- Exasol
- IBM DB2
- ClickHouse
- ODBC
- Sistema de archivos:
Le permiten realizar operaciones en varios tipos de sistemas de archivos, como leer, escribir, copiar, eliminar, mover, comprimir, descomprimir, etc.- Local
- FTP
- SFTP
- HDFS
- S3
- Samba
- OneDrive
- GoogleDrive
- Servicios:
Le permiten aprovechar las llamadas HTTP o a varios tipos de servicios como Nakivo, Google Analitics, etc. - Lógicas:
Le permiten crear una capa de lógica que vincula las diversas operaciones: por ejemplo, condiciones (if), bucles iterativos (for y foreach), asignaciones de variables… - Utilidad:
Le permiten ejecutar scripts en Python o Bash, enviar correos electrónicos, activar el depurador, etc.
Al dividir las tareas en pequeñas operaciones independientes, tiene mayor precisión, granularidad y puede crear casos de uso específicos para necesidades específicas.
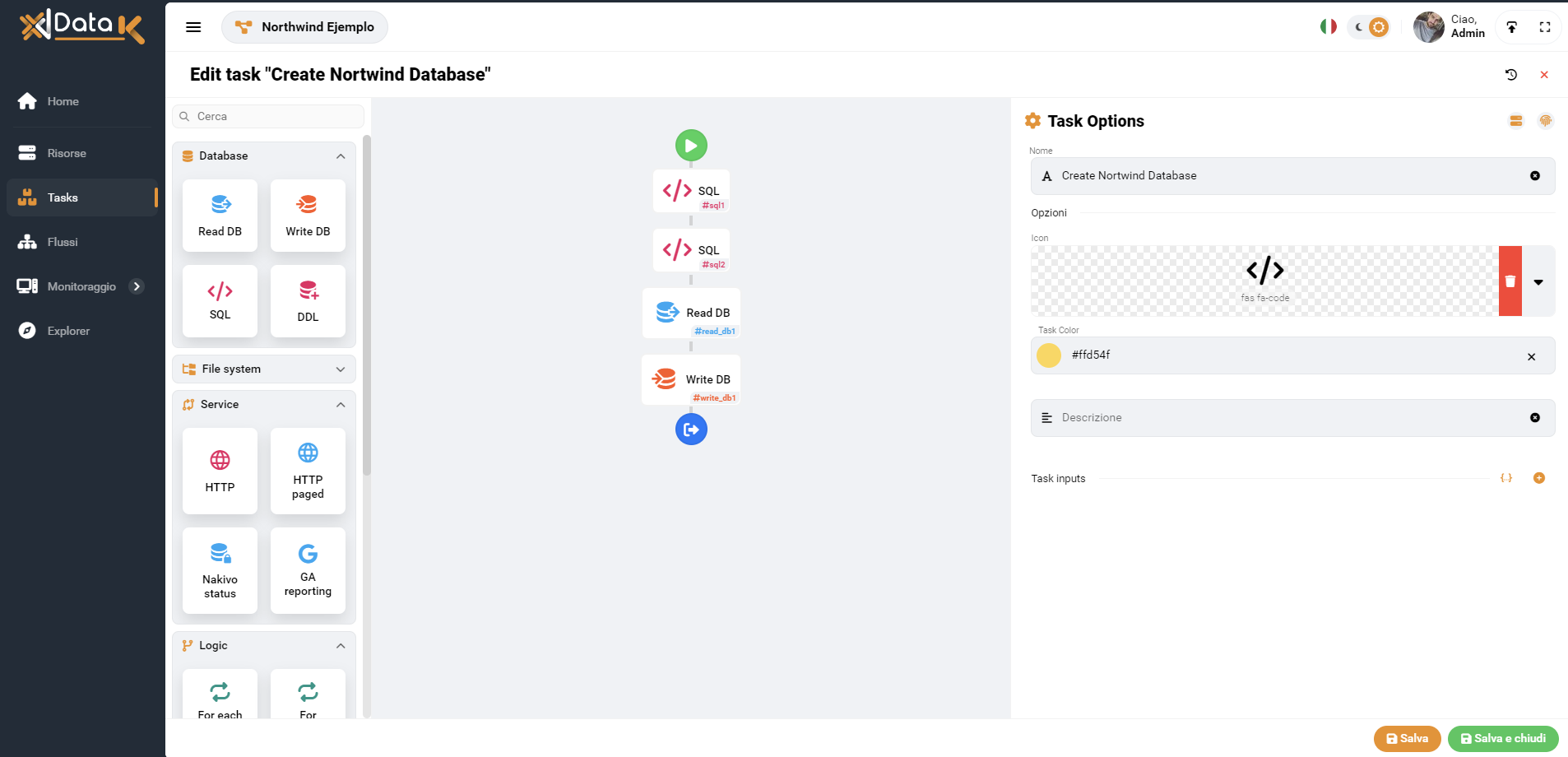
Flujos
Las corrientes también se han rediseñado por completo.
Ahora se pueden conectar dos tipos de objetos de forma paralela o secuencial en un flujo:
- Tareas
- Comportamientos
Las tareas se definen a nivel de aplicación mientras que los comportamientos pueden ser de 5 tipos
- Comenzar:
Punto de inicio del flujo - Salidas:
Objeto que permite la salida de vídeo de una tarea a la que está vinculado - Condición:
Elemento que permite la evaluación de una condición dada y puede crear una encrucijada en la ejecución de un flujo - Variable:
Las variables son un tipo de bloque que se puede usar en un flujo que le permite definir valores para pasar a cualquier otro bloque dentro del propio flujo, por lo que puede crear tareas generalizadas que se pueden usar varias veces con diferentes parámetros, disminuyendo el duplicidad de tareas. Las entradas personalizadas usan la sintaxis${key}y son útiles cuando se debe insertar una entrada dentro de un texto, como en el cuerpo de un correo electrónico, dentro de un script sql o en el contenido que se va a escribir en un archivo. - Global:
Para definir un parámetro que entra en la entrada de todas las tareas en el flujo
Automatización de canalización de datos sin código
Programe la recopilación o carga de datos sin ninguna habilidad de codificación. Conecte fuentes y destinos una vez y déjelos funcionando.